
I earned the Databricks Certified Associate Developer for Apache Spark certification this winter through Nyla’s Continuous Learning benefit program, which provides employees with up to $5000 per year to use for classes, conferences, certifications, or dedicated study hours. This exam costs $200 and can be taken in an on-demand, remote fashion.
The exam has 2 main focus areas:
- Spark Architecture (both Conceptual and Applied Understanding)
- Spark DataFrame API
The exam can be taken in either Scala or Python formats. I passed the Python (PySpark) version. While Databricks is in the name, this is largely due to Databricks being the certificate/exam admin, rather than the exam itself focusing on Databricks. The exam provides you with 2 hours to complete 60 multiple-choice questions.
Spark Introduction
Apache Spark is a unified engine, tailor-made to tackle parallel, large-scale distributed data processing. [1],[2] According to the Spark homepage, Spark is “the most widely-used engine for scalable computing. Thousands of companies, including 80% of the Fortune 500, use Apache Spark™. Over 2,000 contributors to the open source project from industry and academia.”
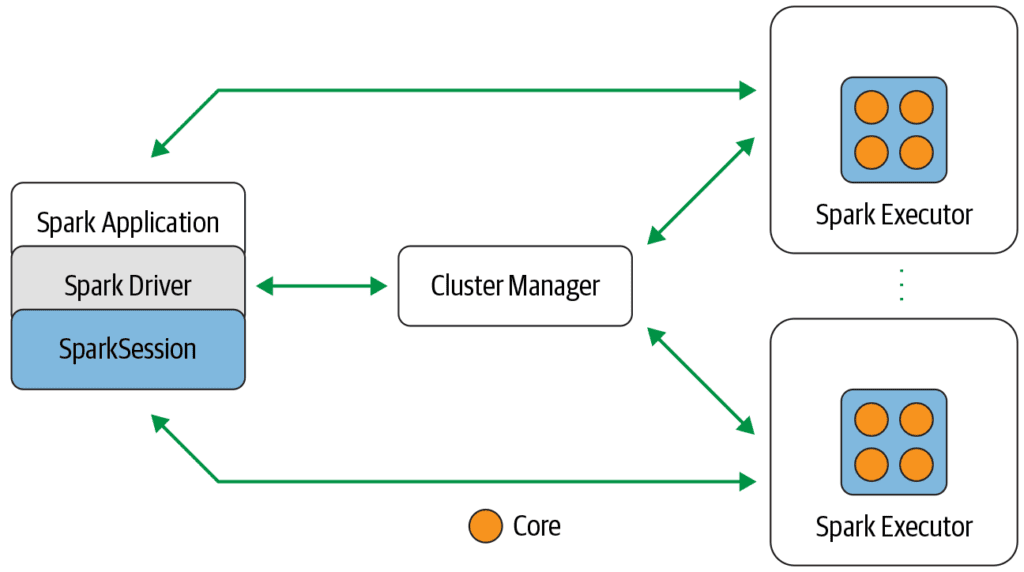
Why learn and use Spark? [1], [2]
Spark allows you to address big data challenges by harnessing the power of a cluster of servers to complete processing rather than a single machine. Spark’s parallel processing engine can dramatically increase the speed of your compute jobs and enable processing runs to complete that would otherwise fail due to the sheer size of the data involved. Spark has a speed advantage over other distributed computing offerings, namely Hadoop Map Reduce, since Spark processes data in memory.
Spark gives developers the choice of leveraging Python, Java, Scale, R, or Scala. The internal guts of the engine are abstracted away from the developer by the underlying API.It allows you to read and write data to a wide variety of sources – csv, Amazon S3, MongoDB, RDBMs, and Apache Delta, among many others.
Spark’s Delta tables provide data versioning and time travel, particularly useful for data engineering pipelines. Also, its integration with Databricks provides seamless development and management interfaces, and deployment to cloud platforms. Spark supports Batch and Streaming jobs and it also supports machine learning and network graph analysis. For me personally, Spark has the additional relevance of being the engine that drives the enterprise platform I am currently working with on contract with Nyla.
Study Prep
I passed the exam after about 50 hours of self-study. Because the exam is stand-alone (it does not come packaged within a course), I recommend the following study resources:
- Udemy Practice Exams (review your exam results and the correct answers thoroughly)
- This Databricks Certified Developer for Spark 3.0 Practice Exams course was the most helpful and well-prepared with thorough answer explanations. Provides 3 practice exams.
- This Databricks Certified Apache Spark 3.0 TESTS (Scala & Python) course was also helpful in that it provided more repetition and practice, but it contained several spelling and logic errors, the answer explanations were not as thorough as the first course above or they were not provided at all. The exams in this course also had some question/answer formats that were different from the actual exam. Provides 2 practice exams.
- I recommend becoming extremely familiar with the Spark API . The API is provided during the exam but you cannot CTRL+F to find what you need. Study the API content to the point where you have memorized the accepted parameters for the most common functions. Also, learn the layout and format of the API so that during the exam you know how to navigate the API to reference less common functions or other details you may forget.
- Review the following two books:
- Spark: The Definitive Guide
- Learning Spark (2nd Edition)
- I also recommend browsing more recent Medium blog posts on study techniques for this exam.
Conclusion
Preparing for and passing this exam has proven to be a valuable time investment for me, and I would recommend earning this cert to colleagues as Spark is currently widely-adopted and stands to grow in its level of use across the data science field. So, while your current tech stack may not employ Spark now, you may likely be working on a stack that does in the future.
Learning how to leverage the Spark engine has immediately enabled me to create more complex data pipelines in my current job context and help developers on other teams within the contract and a member of program leadership successfully troubleshoot their own code. This training also enables me to authoritatively train data professionals within my contract’s client base to be able to leverage Spark and Databricks to deliver value on their own.
References:
[1] Damji, Jules S., et al. Learning Spark: Lightning-Fast Data Analytics . 2nd ed., O’Reilly Media, 2020.
[2] Chambers, Bill, and Matei Zahari. Spark: The Definitive Guide. O’Reilly, 2018.
